Погледајмо сада ицонв услужни програм Линука у његовој терминалној конзоли. Дакле, извршавали смо инструкцију „ицонв“ са заставицом „-л“ да бисмо приказали све познате и најчешће коришћене скупове кодираних знакова на екрану нашег терминала. Приказаће кодиране скупове знакова заједно са њиховим алиасима. Можете видети дугачку листу кодираних скупова знакова након што се мало померите надоле.
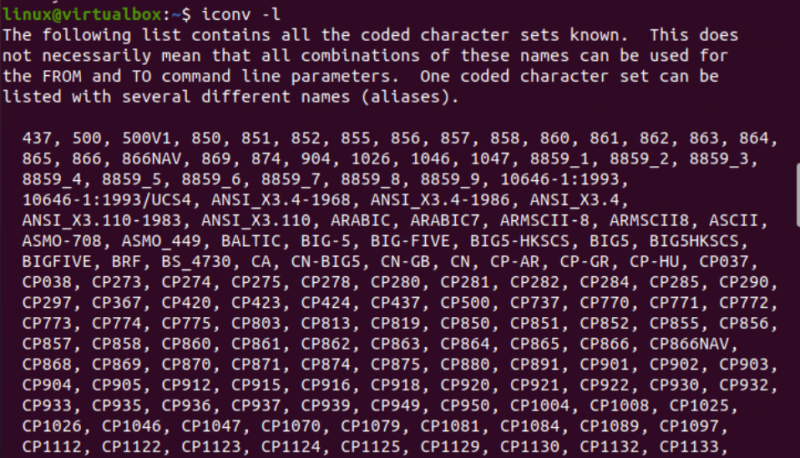
Сада је време да почнете са имплементацијом команде ицонв у Линуку. Прво, потребне су нам различите врсте датотека у нашем систему да бисмо претворили једну врсту датотеке у другу. Дакле, користимо упит „тоуцх“ на терминалу конзоле да креирамо три различите датотеке, тј. тип Јава, тип Ц и тип текста. Наводећи тренутни садржај директоријума, у њему ћете пронаћи новогенерисане датотеке.
Након тога, погледаћемо тип сваке датотеке посебно користећи упит „датотека“ заједно са именом сваке датотеке. Овом упиту је потребна опција „-И“ за приказ типа скупа знакова за кодирање за сваку датотеку посебно. Ако сте заборавили да користите опцију „-И“, уместо тога користите заставицу „—миме“. Обе заставице „-И“ и „—миме“ раде исто.
Сада, након извршења инструкције „филе“ за датотеку типа „ткт“, добили смо „УС-АСЦИИ“ кодирање типа карактера. Док се користи иста инструкција за Јава и Ц датотеке, показује да обе датотеке садрже кодирање типа знакова „БИНАРИ“. Уз то, ово упутство показује да су сва ова три фајла празна.
Сада ћемо илустровати употребу ицонв инструкције на конзоли за конвертовање одређене датотеке кодирања скупа знакова у друго кодирање скупа знакова. Пре тога морамо додати неки код или податке у наше датотеке. Стога смо додали Јава код у датотеку “тект.јава”, Ц код у датотеку “тект.ц” и додали текстуалне податке у датотеку “тест.ткт”. Упит цат је коришћен овде за приказ садржаја све три датотеке, као што је приказано у наставку:
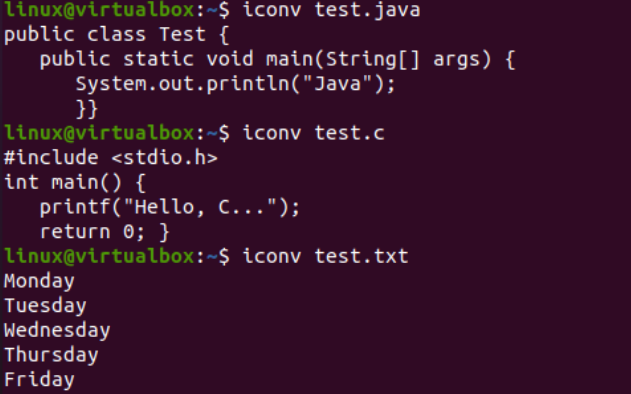
Сада када смо успешно додали податке, поново ћемо видети кодирање скупа знакова ових датотека. Дакле, пробали смо исту инструкцију за датотеку унутар љуске са ознаком “-И” и називима датотека, тј. тест.ткт, тест.јава и тест.ц. Извођење ове три инструкције одвојено за све три датотеке показује да је кодирање скупа знакова ажурирано за Јава и Ц датотеке док је остало исто за текстуалну датотеку, тј. УС-АСЦИИ. Кодирање Јава и Ц датотека је раније било „бинарно“; сада је „УС-АСЦИИ“. Такође, показује да текстуална датотека садржи обичне текстуалне податке, док друге две датотеке кода садрже скрипте као садржај.

Време је да извршите стварни задатак потребан за овај чланак, то јест, претворите једно кодирање у друго помоћу команде ицонв у љусци. Стога смо користили инструкцију „ицонв“ унутар терминала љуске са привилегијама „судо“. Ова команда узима опцију “-ф” која означава “фром”, а “-т” опцију означава “то”, односно, од једног кодирања до другог.
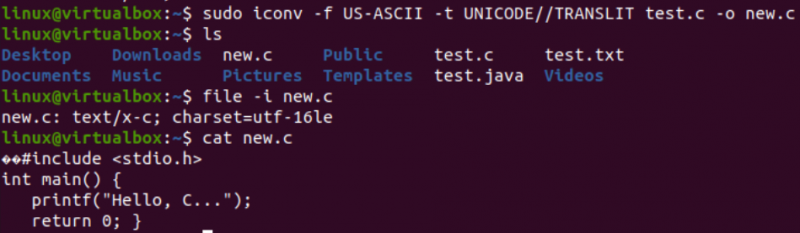
Након опције „-ф“, морате навести кодирање које ваша датотека већ има, тј. УС-АСЦИИ. Док после опције „-т“, морате да наведете кодирање које желите да замените старим кодирањем, тј. УНИЦОДЕ. Морате да наведете име датотеке која се користи као извор са –о опцијом да бисте креирали њену слику објекта. Слика објекта би била друга датотека, тј. „нев.ц“, истог типа, али са новим кодирањем и истим подацима.
Након извршења следеће инструкције, добићете нову датотеку у истом директоријуму, односно према „лс“ упиту. Сада ћемо проверити кодирање скупа знакова нове датотеке генерисане коришћењем ицонв инструкције. Поново ћемо користити инструкцију „датотека“ са опцијом „-И“ и новим именом датотеке, тј.
Видећете да се скуп знакова за ову нову датотеку разликовао од скупа знакова старе датотеке, односно, скуп знакова УТФ-16ЛЕ. То је зато што смо превели УС-АСЦИИ кодирање у УНИЦОДЕ кодирање користећи ицонв инструкцију за нашу нову.ц датотеку. Упит „мачка“ је приказао исти Ц код унутар датотеке, али је почео са неким Уницоде знаковима, као што је већ представљено.
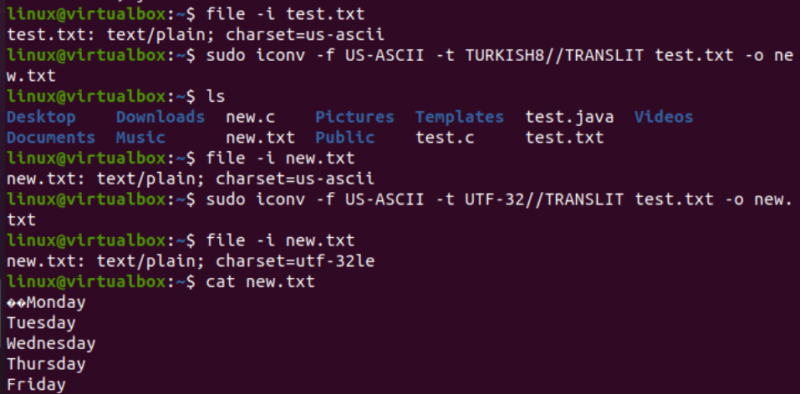
На врло сличан начин променићемо кодирање текстуалне датотеке тест.ткт. Упутство за фајл показује да има УС-АСЦИИ кодирање скупа знакова. Команда ицонв је коришћена у истом формату за претварање кодирања датотеке тест.ткт из УС-АСЦИИ у ТУРКИСХ8. Видећете да то не мења амерички АСЦИИ у турски.
Након овога, користили смо исту команду да покријемо УС-АСЦИИ до УТФ-32 кодирање скупа знакова за исту датотеку. Овог пута ради. То је зато што понекад може доћи до проблема при претварању једног скупа кодирања у други, или га други кодирање можда не подржава.
Закључак
У овом чланку се говорило о томе како да користите ицонв Линук упутства за претварање једног скупа знакова за кодирање у други користећи њихове псеудониме. На овај начин, морали смо да креирамо неколико датотека различитих типова.