Направите колекцију
Пре употребе индекса, морамо да креирамо нову колекцију у нашем МонгоДБ. Већ смо креирали један и убацили 10 докумената под називом „Думми“. Функција финд() МонгоДБ приказује све записе из колекције „Думми“ на екрану љуске МонгоДБ испод.
тест> дб.Думми.финд() 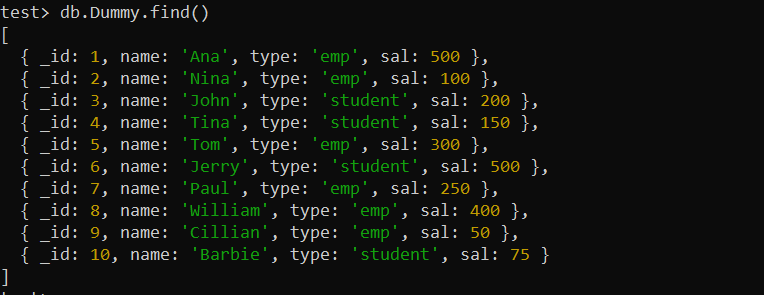
Изаберите Тип индексирања
Пре успостављања индекса, прво морате да одредите колоне које ће се обично користити у критеријумима упита. Индекси добро раде на колонама које се често филтрирају, сортирају или претражују. Поља са великом кардиналношћу (много различитих вредности) су често одличне опције за индексирање. Ево неколико примера кода за различите типове индекса.
Пример 01: Индекс једног поља
То је вероватно најосновнији тип индекса, који индексира једну колону да би повећао брзину упита за ту колону. Овај тип индекса се користи за упите у којима користите једно кључно поље за испитивање записа збирке. Претпоставимо да користите поље „типе“ за упите о записима колекције „Думми“ у оквиру функције проналажења као у наставку. Ова команда би прегледала целу колекцију, што би могло потрајати да би се велике колекције обрадиле. Дакле, морамо да оптимизујемо перформансе овог упита.
тест> дб.Думми.финд({типе: 'емп' })
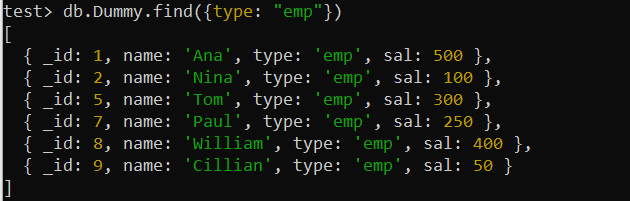
Записи горње Думми колекције су пронађени помоћу поља „тип“, тј. садрже услов. Стога се овде може користити индекс са једним кључем за оптимизацију упита за претрагу. Дакле, користићемо функцију цреатеИндек() МонгоДБ-а да креирамо индекс у пољу „типе“ колекције „Думми“. Илустрација коришћења овог упита приказује успешно креирање индекса са једним кључем под називом „типе_1“ на љусци.
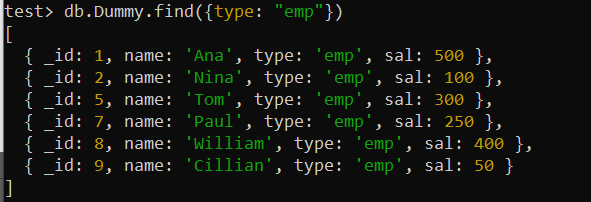
тест> дб.Думми.цреатеИндек({ типе: 1 })Хајде да користимо упит финд() када добијемо коришћењем поља „типе“. Операција ће сада бити знатно бржа од претходно коришћене функције финд() пошто је индекс на месту јер МонгоДБ може да користи индекс за брзо преузимање записа са траженим насловом посла.
тест> дб.Думми.финд({типе: 'емп' })
Пример 02: Сложени индекс
Можда ћемо желети да тражимо артикле на основу различитих критеријума у одређеним околностима. Примена сложеног индекса за ова поља може помоћи у побољшању перформанси упита. Рецимо, овог пута желите да претражујете из колекције „Думми“ користећи више поља која садрже различите услове претраживања док се упит приказује. Овај упит је тражио записе из колекције у којој је поље „типе“ постављено на „емп“, а поље „сал“ је веће од 350.
Логички оператор $гте је коришћен за примену услова на поље „сал“. Укупно два записа враћена су након претраживања целе збирке, која се састоји од 10 записа.
тест> дб.Думми.финд({типе: 'емп' , сал: {$гте: 350 } }) 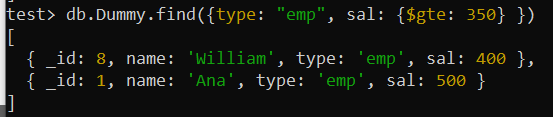
Хајде да направимо сложени индекс за горе поменути упит. Овај сложени индекс има поља „типе“ и „сал“. Бројеви „1“ и „-1“ представљају растући и опадајући ред, респективно, за поља „типе“ и „сал“. Редослед колона сложеног индекса је важан и треба да одговара обрасцима упита. МонгоДБ је дао име „типе_1_сал_-1“ овом сложеном индексу како је приказано.
тест> дб.Думми.цреатеИндек({ типе: 1 , воља:- 1 }) 
Након коришћења истог упита финд() за тражење записа са вредношћу поља „типе“ као „емп“ и вредношћу поља „сал“ већом од 350, добили смо исти излаз са малом променом редоследа у поређењу са претходним резултатом упита. Запис веће вредности за поље „сал“ је сада на првом месту, док је најмањи на најнижем према „-1“ постављеном за поље „сал“ у сложеном индексу изнад.
тест> дб.Думми.финд({типе: 'емп' , сал: {$гте: 350 } }) 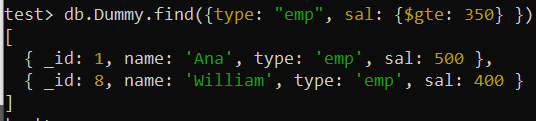
Пример 03: Индекс текста
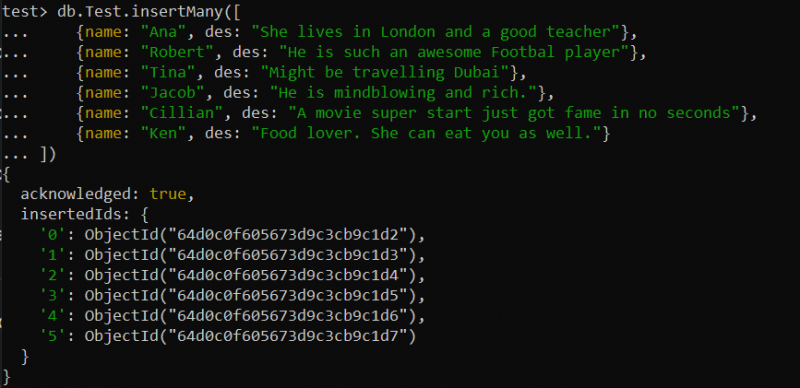
Понекад можете наићи на ситуацију у којој би требало да се бавите великим скупом података, као што су велики описи производа, састојака итд. Текстуални индекс може бити користан за претраживање целог текста у великом текстуалном пољу. На пример, креирали смо нову колекцију под називом „Тест“ у оквиру наше тестне базе података. Уметнуто је укупно 6 записа у ову колекцију помоћу функције инсертМани() према доњем упиту финд().
тест> дб.Тест.инсертМани([{име: 'Ана' , од: 'Она живи у Лондону и добар је учитељ' },
{име: 'Роберт' , од: 'Он је тако сјајан фудбалер' },
{име: 'од' , од: “Можда путује Дубаи” },
{име: 'Јаков' , од: 'Он је невероватан и богат.' },
{име: 'Циллиан' , од: 'Супер почетак филма је стекао славу за неколико секунди' },
{име: 'Кен' , од: 'Љубитељица хране. Она може и тебе да поједе.' }
])
Сада ћемо креирати текстуални индекс у пољу „Дес“ ове колекције, користећи МонгоДБ-ову функцију цреатеИндек(). Кључна реч „текст“ у вредности поља приказује тип индекса, који је „текст“ индекс. Назив индекса, дес_тект, је аутоматски генерисан.
тест> дб.Тест.цреатеИндек({ дес: 'текст' })Сада је функција финд() коришћена да изврши „претрагу текста“ у колекцији преко индекса „дес_тект“. Оператор $сеарцх је коришћен за тражење речи „храна“ у записима о прикупљању и приказивање тог одређеног записа.
тест> дб.Тест.финд({ $тект: { $сеарцх: 'храна' }}); 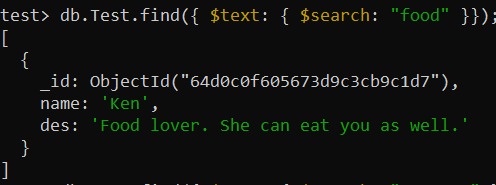
Провери индексе:
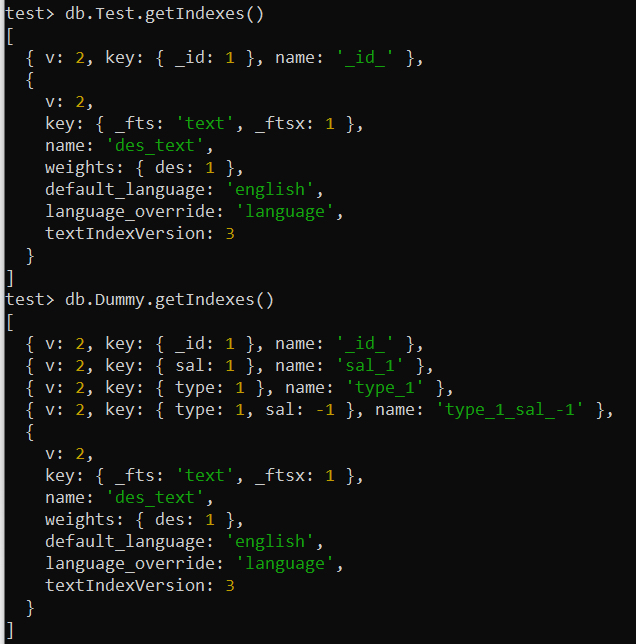
Можете проверити и навести све примењене индексе различитих колекција у вашем МонгоДБ. За ово користите метод гетИндекес() заједно са именом колекције на екрану ваше љуске МонгоДБ. Ову команду смо користили одвојено за колекције „Тест“ и „Думми“. Ово показује све потребне информације у вези са уграђеним и корисничким дефинисаним индексима на вашем екрану.
тест> дб.Тест.гетИндекес()тест> дб.Думми.гетИндекес()
Испусти индексе:
Време је да избришете индексе који су претходно креирани за колекцију помоћу функције дропИндек() заједно са истим именом поља на које је индекс примењен. Упит у наставку показује да је један индекс уклоњен.
тест> дб.Думми.дропИндек({типе: 1 }) 
На исти начин, сложени индекс се може испустити.
тест> дб.Думми.дроп индек({типе: 1 , воља: 1 }) 
Закључак
Убрзавањем преузимања података из МонгоДБ-а, индексирање је од суштинског значаја за побољшање ефикасности упита. У недостатку индекса, МонгоДБ мора да претражи целу колекцију у потрази за подударним записима, што постаје мање ефективно како се величина скупа повећава. Способност МонгоДБ-а да брзо открије праве записе користећи структуру базе података индекса убрзава обраду упита када се користи одговарајуће индексирање.